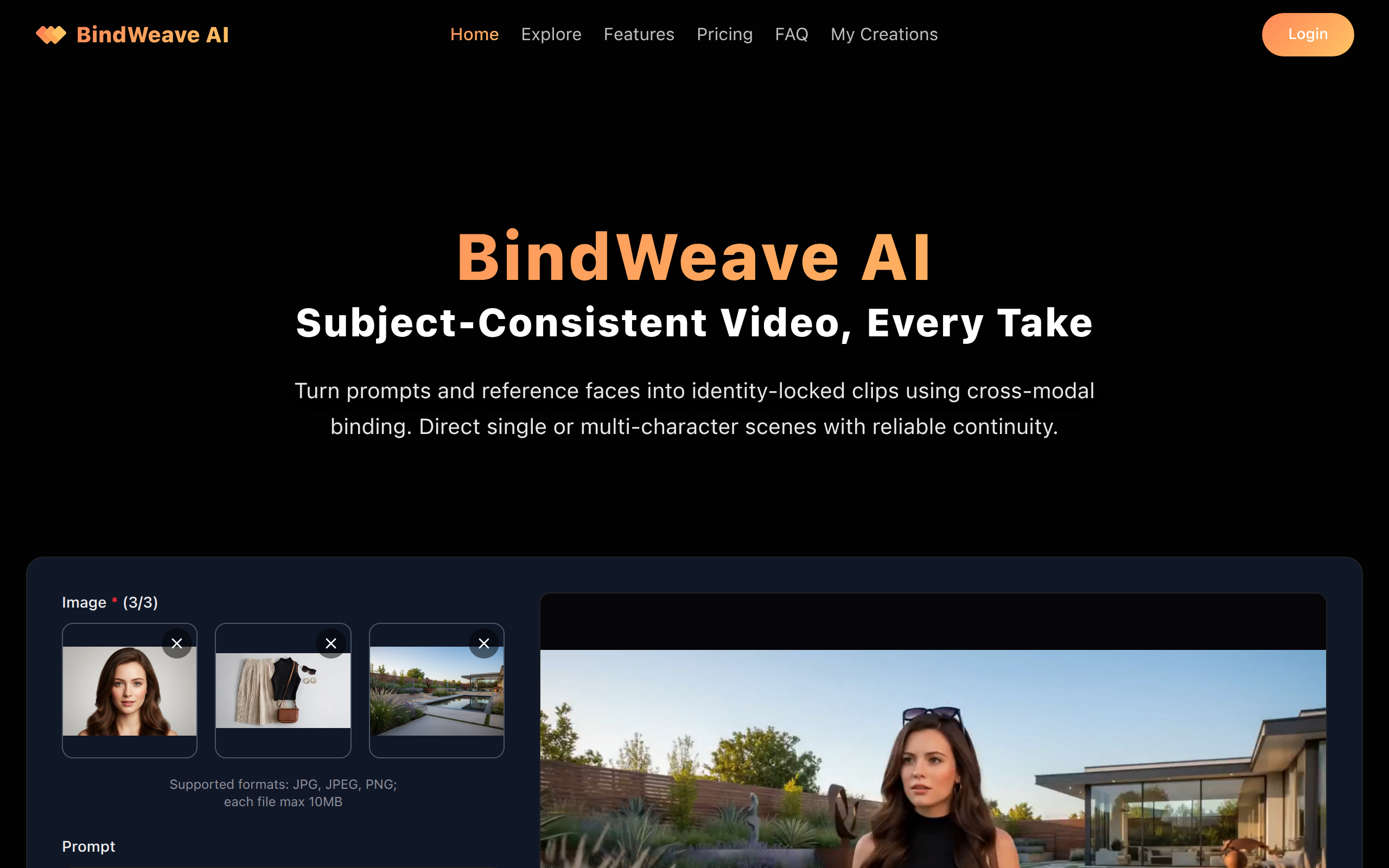
What is BindWeave AI?
BindWeave AI turns text + references into subject-consistent videos using cross-modal integration for single or multi-character scenes.
BindWeave AI's Core Features
✨
Single-human-to-video
Given a single reference photo of the human (face or body), BindWeave generate.
✨
Multi-human-to-video
Given multiple reference images, BindWeave creates prompt-driven multi-person videos that preserve each subject's identity and cleanly depict their interactions, with smooth temporal consistency and no identity swaps.
✨
Human-entity-to-video
Given multiple reference images of people and objects, BindWeave can maintain per‑subject and per‑entity identity consistency, achieve prompt‑accurate and physically plausible human–object interactions, and deliver smooth temporal coherence under occlusions and view changes.